Conductor
由于工作需要,业务代码内耦合的业务流程越来越多,迫切需要一个好的服务编排引擎。经过调研,Conductor是一个经过实际检验非常优秀的服务编排引擎。经过几周的探索,终于把项目Run起来了。详细的调研结果见后文
系统架构
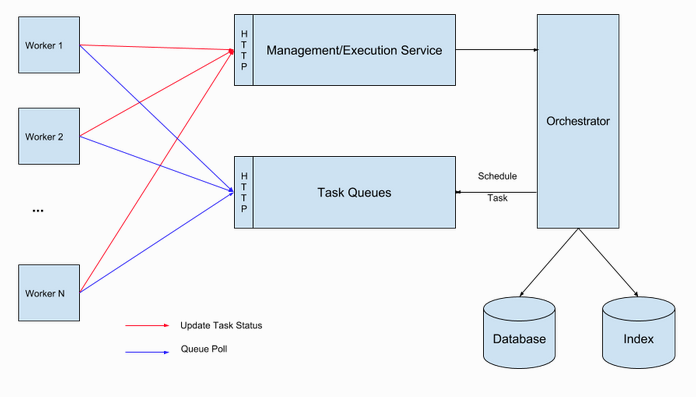
1.Conductor架构图
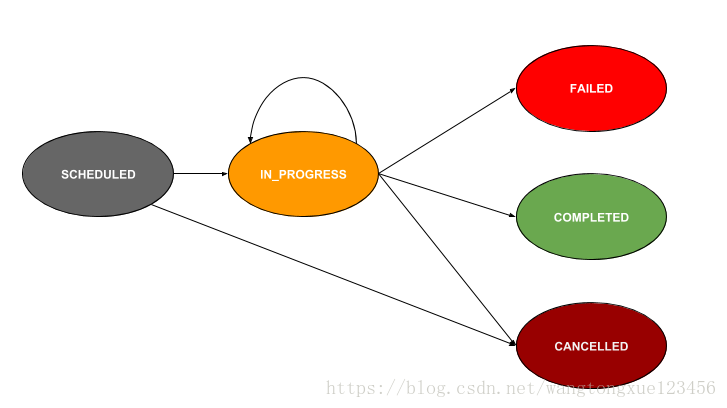
2.任务生命周期
3.调用流程说明
- 首先在conductor server上定义task和workflow
- 通过接口启动workflow
- 编排服务会从存储中取得workflow和其中task的metadata,通过状态机服务判断当前要执行的task放入task queues,并置此task状态为SCHEDULED,等待worker认领
- 启动各微服务worker,在worker中声明当前worker对应的task定义的名字
- worker会轮询conductor server,如果发现有同名的任务被放入task queues里,认领此任务,并更新任务状态为IN_PROGRESS,然后开始执行worker内业务逻辑
- worker中业务逻辑执行完后,根据至执行结果,更新任务状态为COMPLETE或FAIL
- conductor server监听此任务如果变为COMPLETE或FAIL执行下一个节点或重试等逻辑操作,如此往复。
代码结构
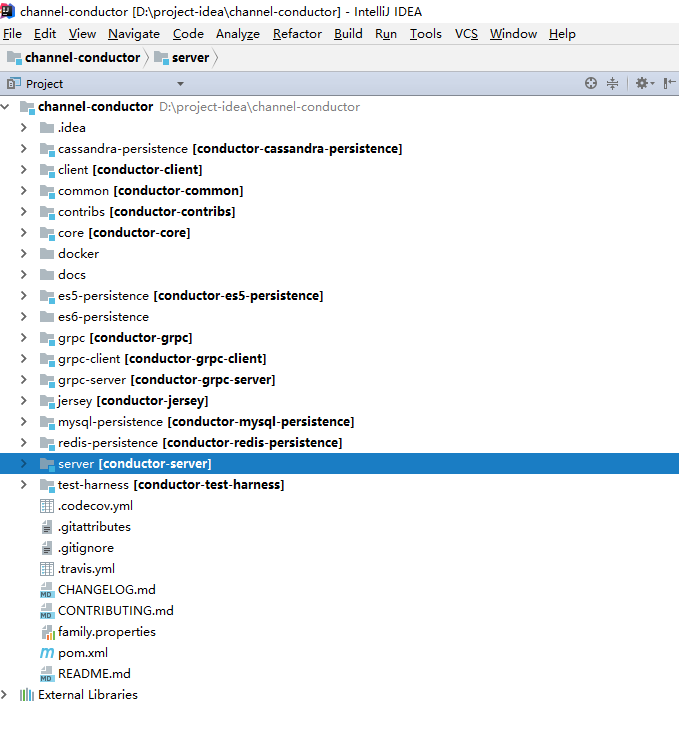
核心代码结构说明
- client层
Conductor的使用场景是服务编排,必然会涉及client和server端也就是说在我们的微服务中的服务中可以使用client端来和conductor的server端进行通信,根据不同状态来执行相应任务。 - server层
负责conductor server端的启动、工作流任务的启动,由server层调用core层实现分布式状态机控制和任务的调度。 - common层
这一层主要涉及的是Task任务和Workflow工作流的元数据和请求参数定义,还有一些工具类。 - core层【核心模块】
这一层主要包括的是核心类,包括:事件、队列功能类,还包括任务类型定义、每种类型任务的具体实现逻辑和映射关系,比如分支条件如何进行判断,逻辑表达式如何解析,并行任务如何执行等等。 - jersey层
这个主要提供的是Swagger接口展示层,通过启动这个模块可以看到一个接口列表页面,用户可以在界面上操作接口实现任务和工作流元数据的编写和上传,还可以在界面上启动工作流引擎等。 - contribs层
亚马逊消息SQS - es-persistence
这一层主要是持久层,根据请求版本不同包括es5和es6二个模块,作用主要包括将任务和工作流元数据保存到es中,还有就是将任务运行时数据进行保存,比如任务执行的状态,执行时间等等。 - mysql-persistence
mysql持久层,存储任务和工作流定义的元数据。 - redis-persistence
redis持久层,存储任务和工作流定义的元数据。 - conductor-cassandra-persistence
cassandra持久层,存储任务和工作流定义的元数据。
grpc、grpc-client、grpc-server是用于支持rpc通信相关的模块
核心类代码【待完善】
技术栈
从github上获取项目
1 | git clone https://github.com/Netflix/conductor.git |
gradle项目转maven项目
- 前端项目:http://gitlab.creditease.corp/loanplatformchannel/channel-conductor-ui.git
- 后端项目(转maven):http://gitlab.creditease.corp/loanplatformchannel/channel-conductor.git
特别注意:gradle转完maven项目后,存在大量包冲突,推荐一个插件“Maven Helper”,非常好用。
启动本地服务器
前端项目启动
- 安装nodejs
- 安装gulp
1
2cnpm install gulp --save-dev
cnpm install --save-dev- 启动项目
1
gulp watch
- 项目启动后,访问地址:http://localhost:3000
后端项目启动
- 下载jetty安装包,并配置jetty启动
- 下载elasticsearch安装包,并且启动elasticsearch服务
- 下载kibana,安装后,启动服务,访问地址:http://localhost:5601,用于管理es数据
- 项目启动后,访问地址:http://localhost:8080
特别注意:1)使用tomcat无法启动conductor,启动时报servlet类型不匹配;
配置工作流
1. 定义任务
- 使用接口:http://localhost:8080/api/metadata/taskdefs
HTTP方法:POST
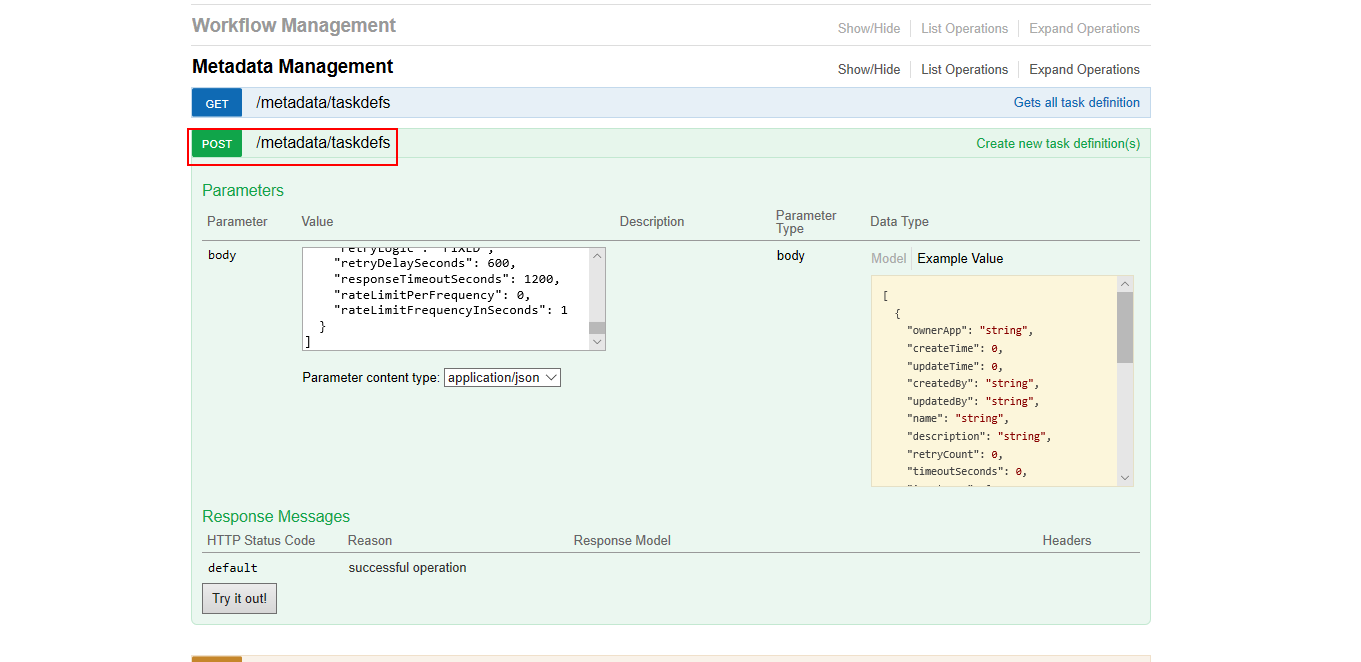
页面查看
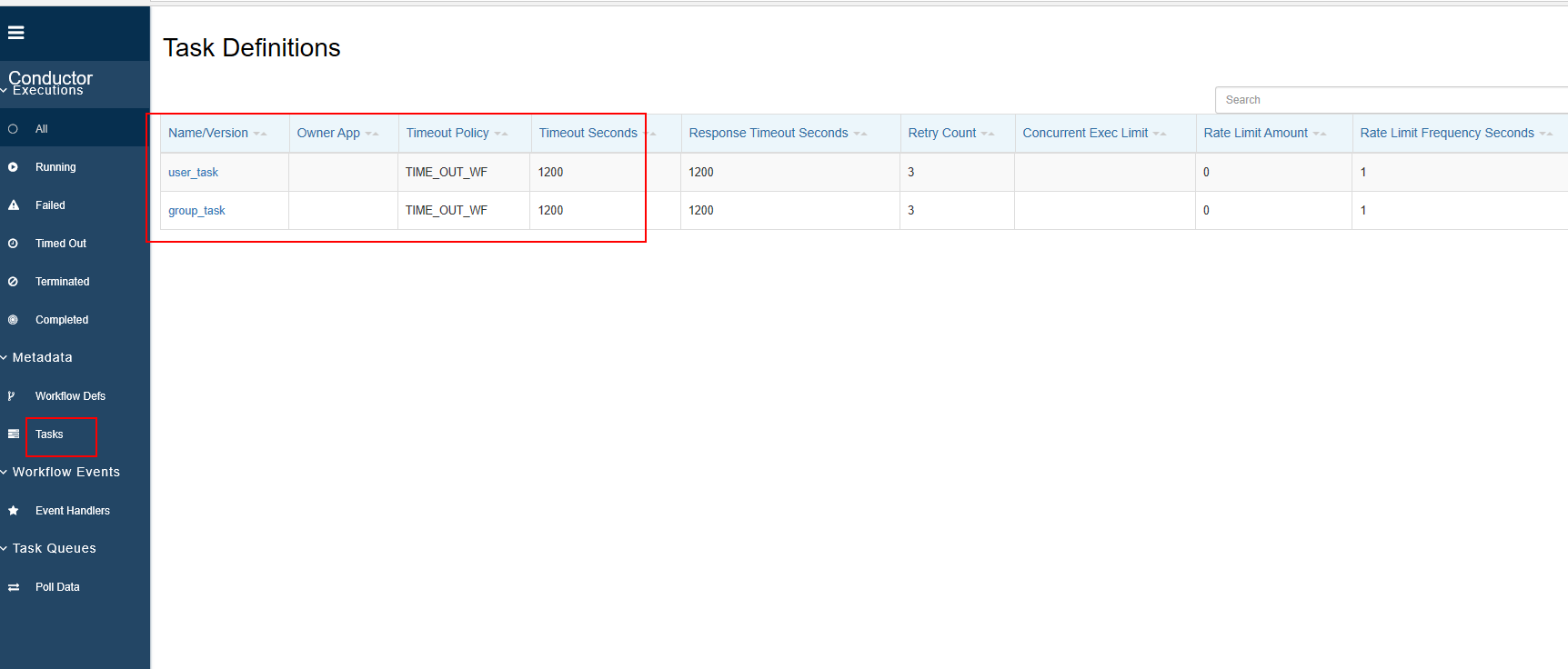
入参示例
1 | [ |
- 参数说明
| 领域 | 描述 | 笔记 |
|---|---|---|
| name | 任务类型 | 唯一 |
| retryCount | 任务标记为失败时尝试重试的次数 | |
| retryLogic | 重试机制 | 看下面的可能值 |
| timeoutSeconds | 以毫秒为单位的时间,在此之后,如果在转换到IN_PROGRESS状态后未完成任务,则将任务标记为TIMED_OUT | 如果设置为0,则不会超时 |
| timeoutPolicy | 任务的超时策略 | 看下面的可能值 |
| responseTimeoutSeconds | 如果大于0,则在此时间之后未更新状态时,将重新安排任务。当工作人员轮询任务但由于错误/网络故障而无法完成时很有用。 | |
| outputKeys | 任务输出的键集。用于记录任务的输出 |
重试逻辑
- FIXED :重新安排任务后的任务 retryDelaySeconds
- EXPONENTIAL_BACKOFF:重新安排之后 retryDelaySeconds * attempNo
超时政策
- RETRY :再次重试该任务
- TIME_OUT_WF:工作流程标记为TIMED_OUT并终止
- ALERT_ONLY:注册计数器(task_timeout)
2. 定义工作流【串行工作流】
- 使用接口:http://localhost:8080/api/metadata/workflow
HTTP方法:POST
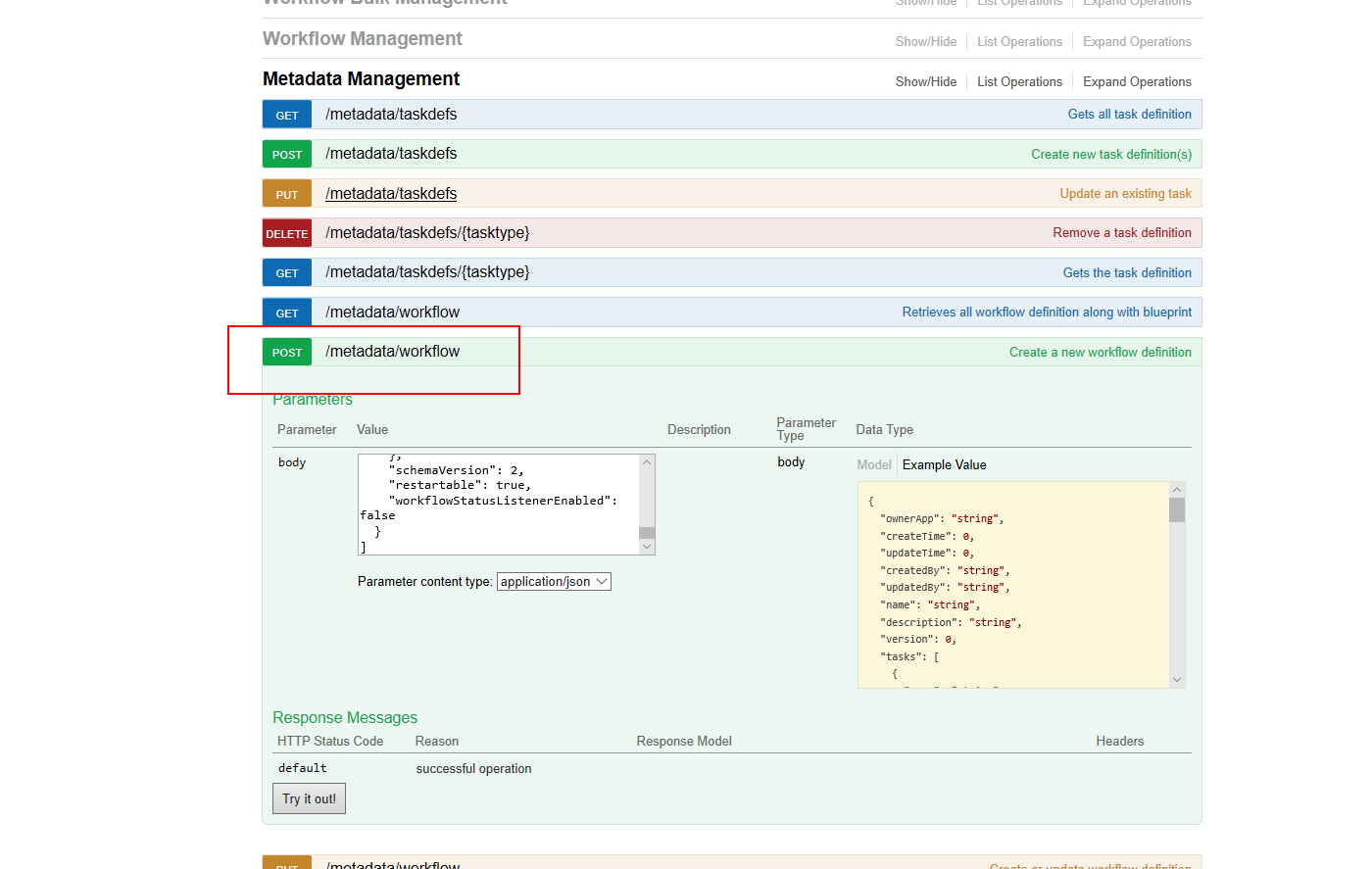
页面查看
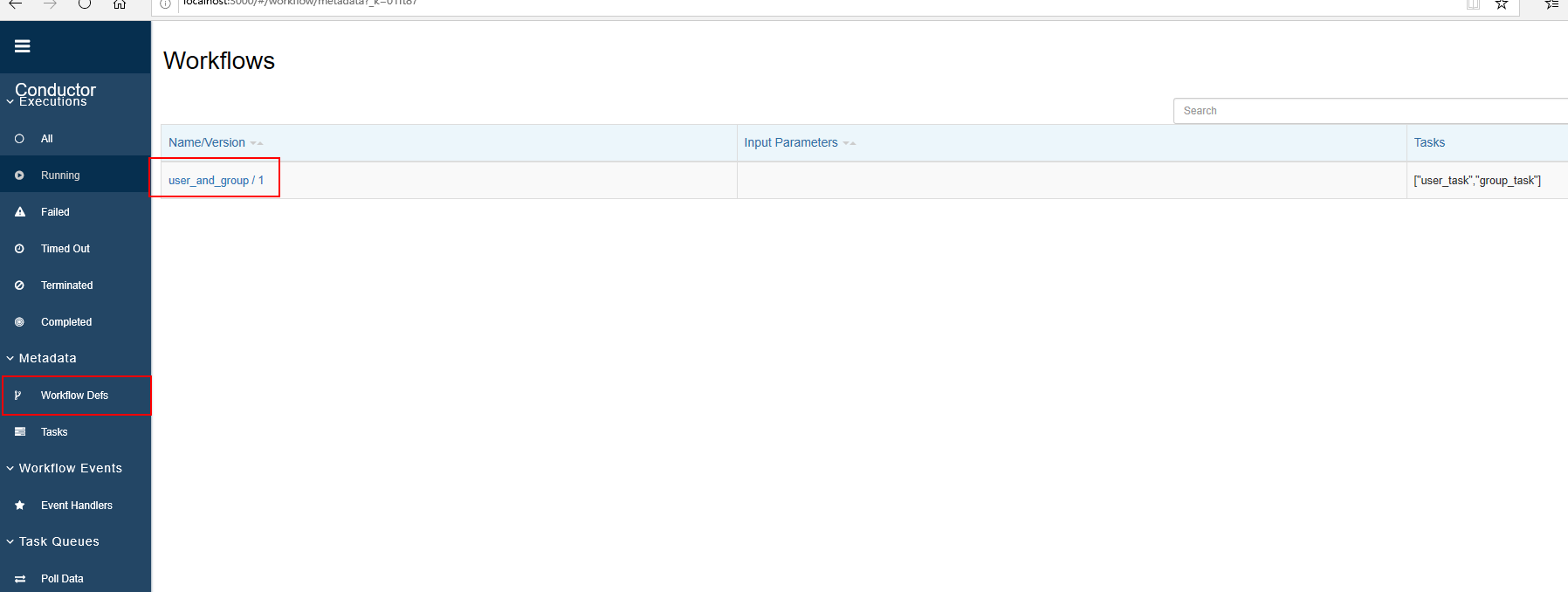
- 入参示例:
1 | { |
- 参数说明
| 领域 | 描述 | 笔记 |
|---|---|---|
| name | 工作流程的名称 | |
| description | 工作流程的描述性名称 | |
| version | 用于标识架构版本的数字字段。使用递增数字 | 启动工作流程执行时,如果未指定,则使用具有最高版本的定义 |
| tasks | 一系列任务定义,如下所述。 | |
| outputParameters | 用于生成工作流输出的JSON模板 | 如果未指定,则将输出定义为上次执行的任务的输出 |
| inputParameters | 输入参数列表。用于记录工作流程所需的输入 | 可选的 |
其中,tasks工作流中的属性定义要按该顺序执行的任务数组。以下是每项任务所需的强制性最低参数:
| 领域 | 描述 | 笔记 |
|---|---|---|
| name | 任务名称。在开始工作流程之前,必须使用Conductor注册为任务类型 | |
| taskReferenceName | 别名用于在工作流程中引用任务。必须是独一无二的。 | |
| type | 任务类型。SIMPLE用于远程工作人员或其中一个系统任务类型执行的任务 | |
| description | 任务描述 | 可选的 |
| optional | 对或错。设置为true时 - 即使任务失败,工作流也会继续。任务的状态反映为COMPLETED_WITH_ERRORS | 默认为 false |
| inputParameters | JSON模板,用于定义给予任务的输入 | 有关详细信息,请参见“接线输入和输出” |
3. 任务执行
- 使用接口:http://localhost:8080/api/workflow/{workname}
HTTP方法:POST
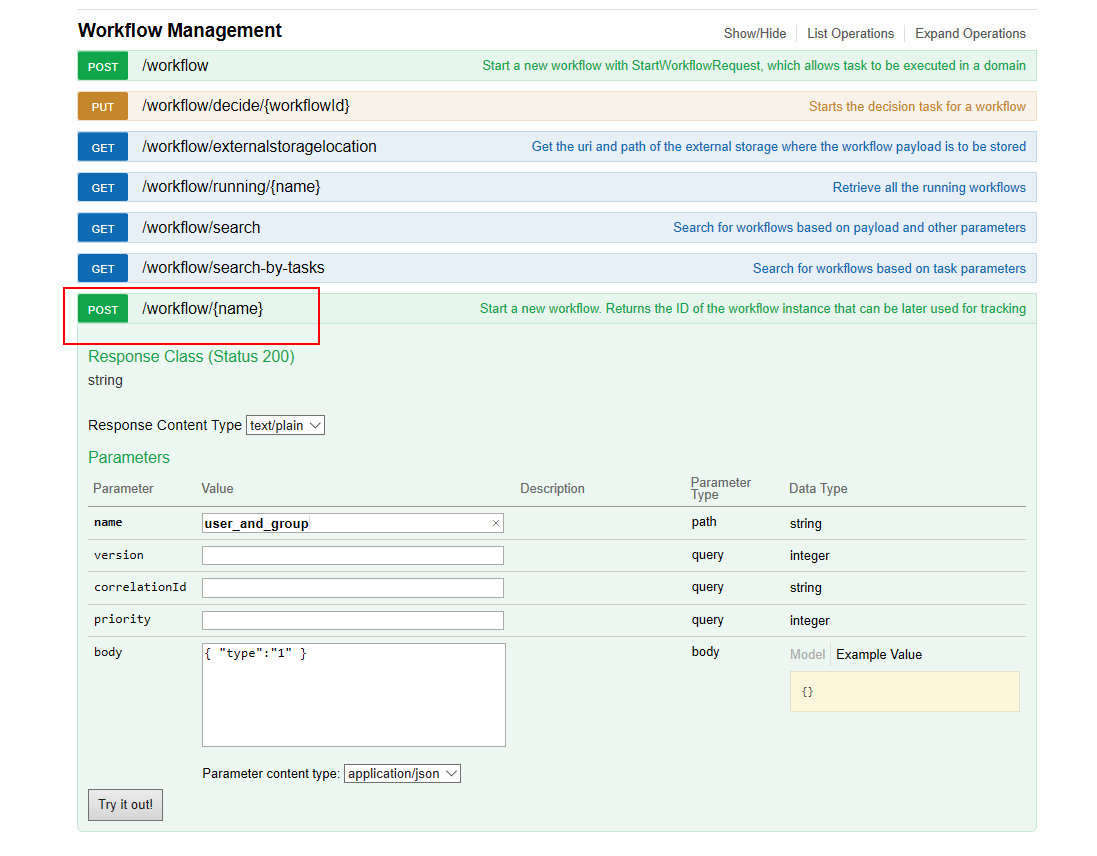
入参示例
在body中定义参数:
1 | { |
4.编写用户任务
目前示例中使用的是HTTP任务,需要编写对应应用rest http接口
1 |
|
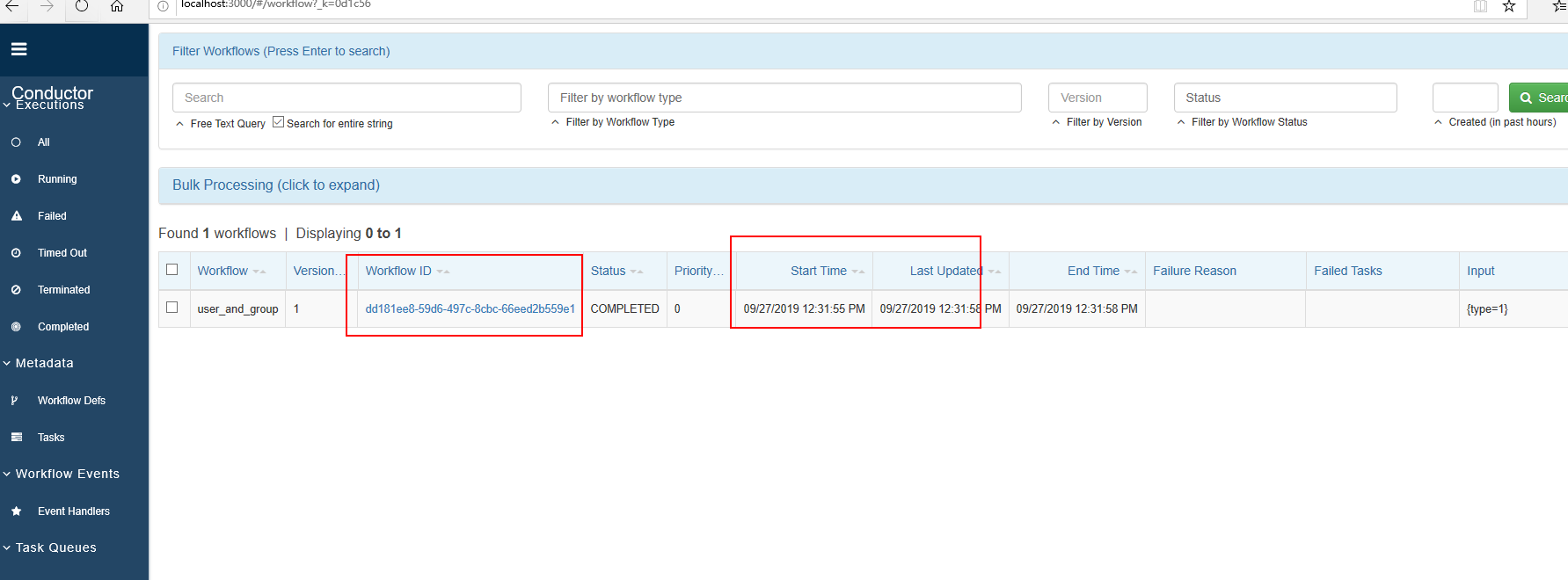
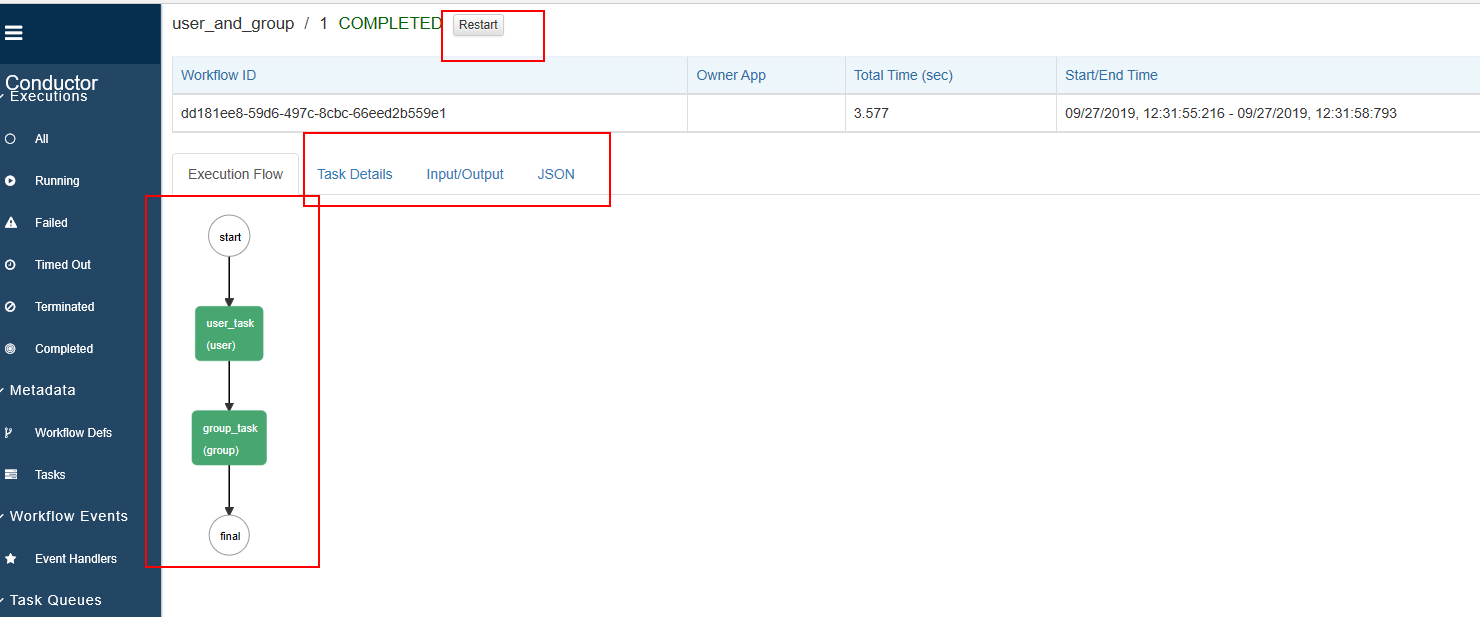
5. 查看执行结果
- 调用接口:http://localhost:8080/api/workflow/{workid}
- HTTP方法: GET
- 页面查看
- 输出内容示例
1 | { |
5.其他工作流【待完善】
除了线性工作量,conductor还支持很多更加复杂的工作流,如并行工作流、分支工作流等
注意事项
- Task和workFlow的定义是放在内存(Memory)里的,服务重启后,信息就丢失了。
- 如果想调整默认配置,可以通过修改com.netflix.conductor.core.config.Configuration类中DB_DEFAULT_VALUE变量值
- 任务执行记录是存储在ES中的,所以,服务重启后,信息依然存在
优缺点分析
Conductor优点
Conductor,帮助我们协调基于微服务的流程,具有以下功能:
- 允许创建复杂的流程/业务流,其中由微服务实现单个任务。
- 基于JSON DSL的定义执行流程。
- 为这些流程提供可见性和可追溯性。
- 在暂停,恢复,重启等周围公开控制语义,以获得更好的devops体验。
- 允许更多地重用现有的微服务,为管理提供更容易的途径。
- 用户界面可视化流程。
- 能够在需要时同步处理所有任务。
- 能够扩展数百万个并发运行的流程。
- 由客户端提取的排队服务支持。
- 能够在HTTP或其他传输上运行,例如gRPC。
为什么不进行点对点编排?
通过点对点任务编排,我们发现随着业务需求和复杂性的增长难以扩展。发布/订阅模型适用于最简单的流程,
但很快就突出了与该方法相关的一些问题:
- 流程“嵌入”在多个应用程序的代码中。
- 通常,围绕输入/输出,SLA等存在紧密耦合和假设,使得更难以适应不断变化的需求。
- 几乎没有办法系统地回答“我们用过程X做了多少”?
Conductor不足
- 定义流程,需要手写DSL文件,对使用者要求太高,需要做前端改造;
- 没有介入权限管理功能,需要改造增加
- 项目是gradle管理的项目,需要转maven
- 配置文件都是本地配置,测试/生产部署的话,需要配置文件做改造
- 汉化工作
- 技术架构跟目前宜信常用架构、技术栈差距明显,对开发者技术要求较高,间接导致运维难度会更大
参考链接
- 服务编排–Conductor
- Netflix Conductor源码分析–总体架构介绍
- conductor介绍
- Netflix Conductor:官方样例搭建
- guice
- Netfiex Conductor安装入门指南以及切换为mysql数据源
- CONDUCTOR 系统任务